Jun 1, 2024
Understanding the protocols behind the Web through low-level socket programming
The Web is the Internet’s main application used worldwide by billions of people. When I started programming my first web apps, I came across some fundamental questions: how do different computers communicate with each other? How can I access, from my home, data located in another part of the globe? What happens under the hood when I open my browser and visit a website, like "https://www.google.com”?
Fortunately, this is not magic: it has been built by humans like me and you, and my goal with this post is to elucidate at least some of the main ideas behind it. We'll write a static file server in C, mostly as an excuse to explore sockets and understand core protocols like HTTP and TCP.
To start, let's make a clear distinction: the Web and the Internet are not the same thing. The careful reader noticed at the beginning of this article: the World Wide Web is just an application of the Internet. But what exactly does that mean?
We need to think of the Internet as a global network of networks, the whole group of interconnected computers (hosts, more precisely) around the planet. You can imagine how complex it is to develop and maintain such a thing, so to help us out, people broke it down into abstraction layers, each with its own responsibilities. These layers range from applications, like the Web, down to the most physical aspects, such as data transmission over copper wire or fiber optics. Let’s have a look at the OSI model and its compacted 4-layer model, TCP/IP:
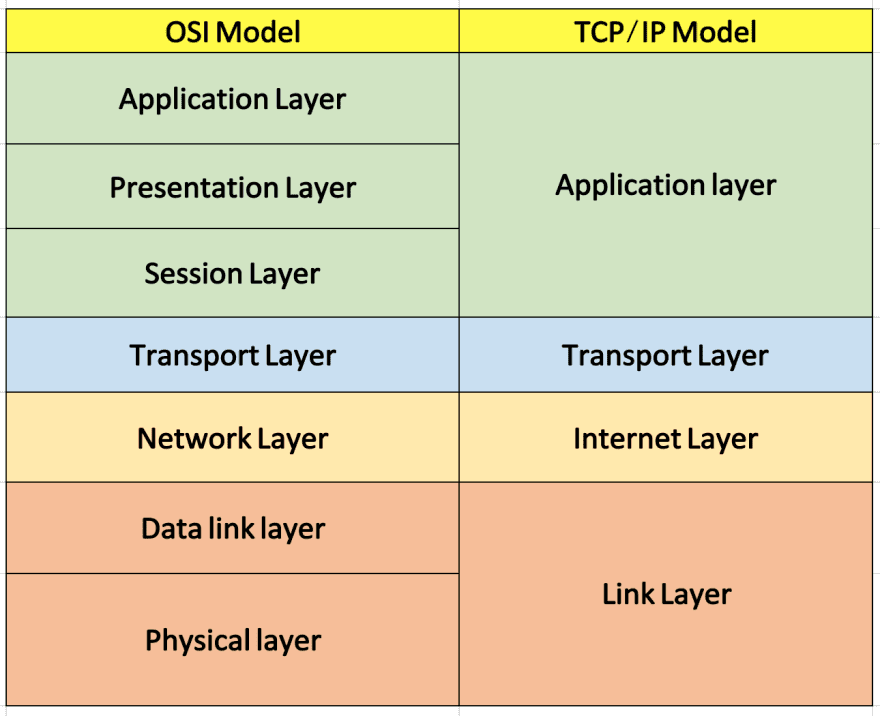
There are several layers, as we can see, and many things going on in each of those. Covering all that in a single article wouldn't be feasible [1]. For that reason, today we'll focus on the two top layers of the TCP/IP model, namely, application and transport, which will already give us a pretty solid understanding of how the Web works.
When two people need to communicate, they usually follow some standards. If you want to ask someone what is the current time, you first greet the person, receive a compliment back, and then ask “what time is it?”. After that, you'd expect to receive a decent response like “it’s 10AM”. If the person replies with “get out of here!” right after your greeting or says “I love meat” as the response to your time request, the communication simply wouldn't happen (even though meat is great indeed).
So is in computer networking: when two computers are communicating over the internet, they need to follow protocols – guidelines that make communication possible, allowing different hosts to compose and parse messages.
Speaking of the Web, at the application layer, we have the Hyper-Text Transfer Protocol (HTTP), the protocol that defines the format of the messages sent from the clients, as well as the messages returned by the servers. Such a protocol is essential to ensure both ends of the communication have clear expectations of what to send and how to handle the received data, among other important features.
When two hosts use HTTP to define how data is structured, there's another important aspect to consider: how these hosts will actually exchange the data. This is where the transport layer comes in. The transport layer's main job is to create a connection that makes it seem like two application processes on different hosts are directly linked. Essentially, it provides a kind of virtual communication link between the two, allowing them to exchange data smoothly.
To link a process (program) to another process, operating systems provide something called a socket, an interface that exposes several communication capabilities, allowing processes to receive and send data through it. In the Web, we ultimately want to connect a process on the server with a process on the client. Sockets serve as the essential conduit, bridging these applications with the underlying transport layer.
In C, here’s how we can set up a networking socket:
The first argument defines the socket domain. Since we are building a web server that will be available on the internet, we choose PF_INET, which stands for protocol family.
In Web applications, we either use UDP (User Datagram Protocol) or TCP (Transmission Control Protocol). In a nutshell, TCP ensures all packets are delivered – in the exact same order – and provides other advanced mechanisms, like congestion control, at the cost of an extra roundtrip. On the other side, UDP is a much simpler transport protocol, ideal for applications that need fast delivery and don’t worry too much about packet losses (e.g. real-time video transmission).
Given that we’re writing a static file web server, we need a reliable channel of communication to ensure all our file data is delivered in the right order. Hence we pass SOCK_STREAM in the second argument to define the socket type and pick TCP as the transport protocol.
Lastly, we pass the protocol type. In most cases there isn’t more than one type available for a given socket within a domain, so we just specify 0.
Now that we’ve created a socket, we need to take two actions with it:
- Bind – we have to plug the socket into a given port so that other processes can identify it and transmit data to it
- Listen – tell the OS that the socket is ready to receive connections
Here’s how we can do it:
I mentioned briefly that TCP is a reliable transportation protocol, but why is that the case?
Before sending any data over the internet, the client performs a SYN (synchronize) request to ensure the server is ready to receive data. When the server receives the request, it responds with an ACK (acknowledge) and another SYN (the other way around) to synchronize with the client. The client receives the ACK from the server as well as the SYN request, and if all is good, returns an ACK indicating that it has received the server’s SYN.
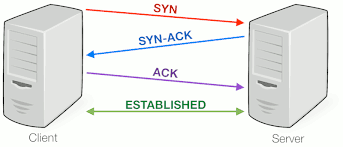
This whole process is known as a three-way handshake; once complete, we say that the connection has been established and the client can proceed with its actual data requests. For this reason, we say that TCP is a connection-oriented protocol, as it ensures both sides are ready to receive or send data.
Returning to our code, now that our server is already listening on port 8000, we’re ready to accept TCP connections. We’ll do this in a while(1) loop so that our server never halts:
Worth noting that, by default, the accept method is blocking, that is, while there are no connections in the queue, the program execution will remain paused until a new connection is requested. Once a connection is established, the accept method creates a new socket for the client and returns its file descriptor.
With the connection established, our server is ready to read the client request:
We start by allocating 4096 bytes of memory using calloc, ensuring all bytes are initialized to \0. Then, we call recv to store this data in the buffer we’ve just created [2].
Great! We have the client data, but what should we do with it? Now HTTP comes into play. The HyperText Transfer Protocol defines how clients should request and how servers should respond. For simplicity, we’ll follow HTTP/1.0 as defined in RFC 1945. Let’s have a look at how client requests are formatted [3]:
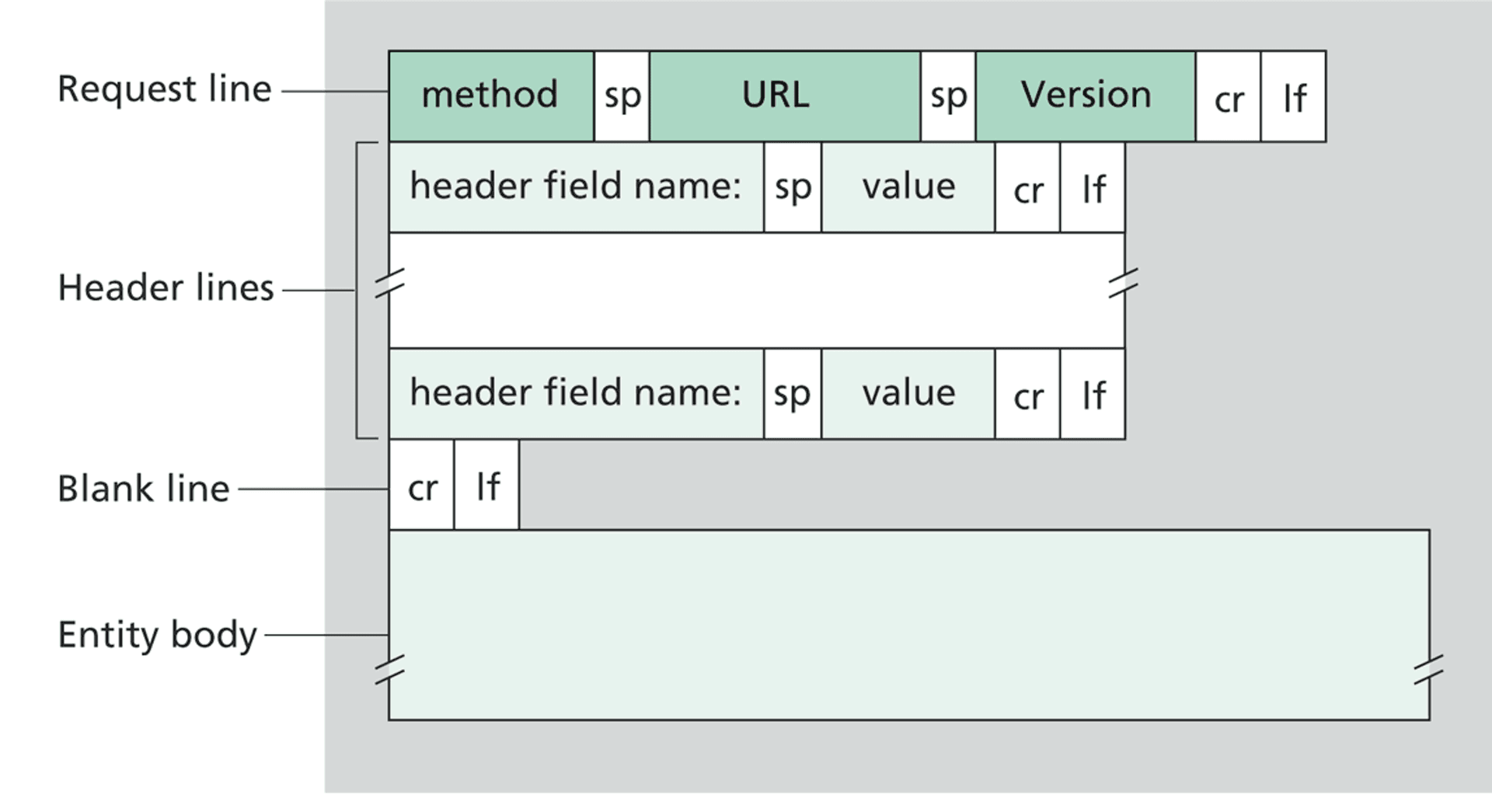
More concretely, here’s an instance of an HTTP request:
For this basic server, we won't worry too much about request headers. We essentially need to parse two things: the request URL and the request method. Let's write a simple parser that receives a request buffer and returns a nice struct with the info we need:
strtok is a helper that lets us break a string (first argument) into tokens based on a delimiter (second argument) – we use that to first get the request method (e.g. “GET” or “POST”), then we use it to retrieve the URL from the first line of the request.
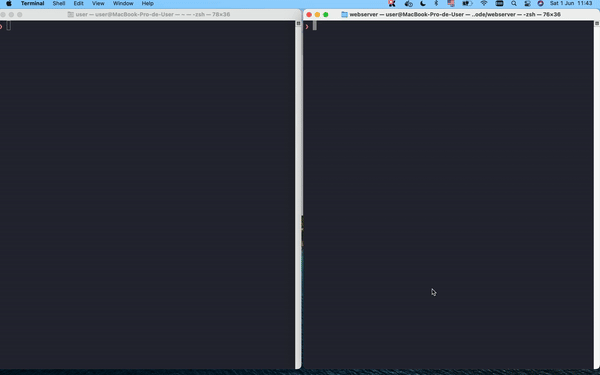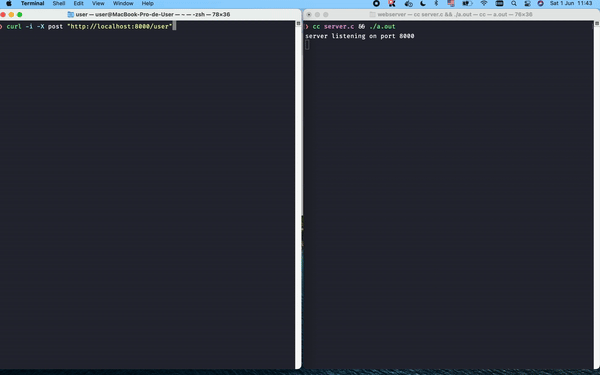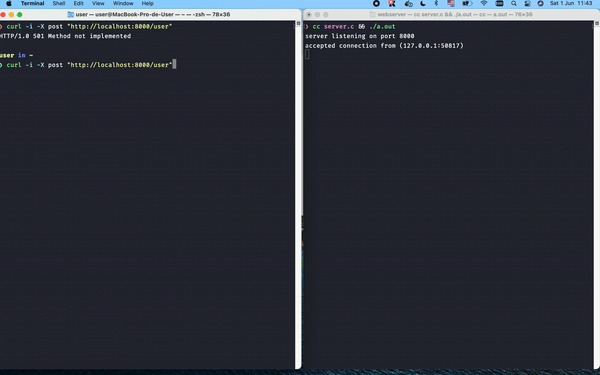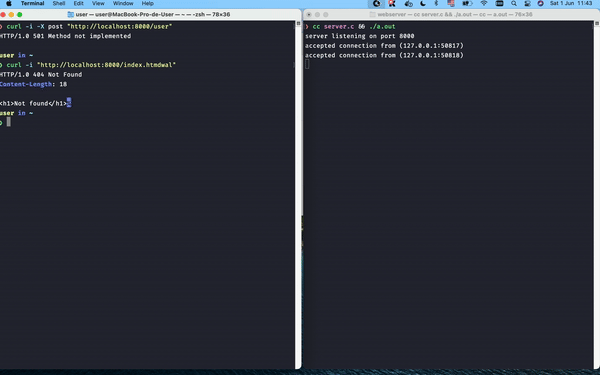
With the parser in place, we can actually process the request. The first thing to be validated is the request method. As a static file server, we should only accept GET requests. Anything beyond that should be answered with a 501 (Method not implemented) [4]
A couple of things are happening now – let’s see it:
- if the parsed request method is not “GET”, we enter into this if block to send a response to the client saying that the provided method hasn’t been implemented, given our server only processes GET requests.
- From the conditional block, we compose the HTTP response. It follows a different structure from the request we saw earlier: we start by specifying the protocol version, in our case HTTP/1.0, then a status code (501) followed by a status message (Method not implemented). Then, to indicate the end of the response we add two CRLFs – one to indicate the end of the status line, and another to indicate the end of the headers (we’re not appending any headers to this response). Here’s a breakdown of the HTTP response [5]:
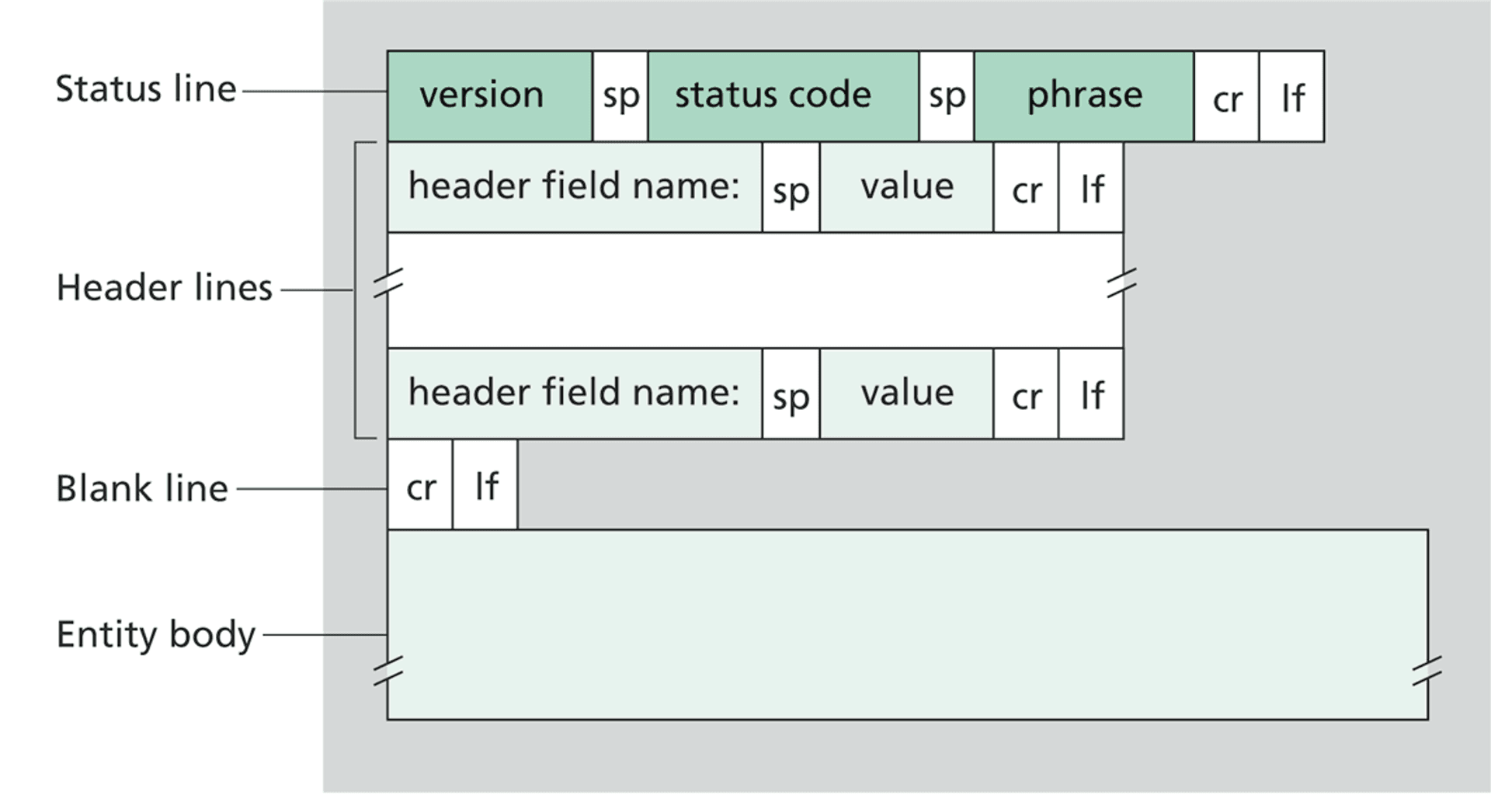
- As we’re implementing HTTP/1.0, we immediately close the connection once the response is sent. If we were to respect HTTP/1.1, for instance, we would keep the connection alive by default and close it based on the request headers. We call this persistent connection, a bit beyond the scope of this post, but an important concept to keep in mind when implementing a real server.
Now that we're skipping and responding to non-supported methods, we can process the file requests based on the URL we parsed earlier. The first thing we have to do is ensure the requested file is present in the system. If not, we should return a 404 message, indicating that the file has not been encountered:
The response here is a bit more complete when compared to the other one we returned above: after the status line, we include the Content-Length header, which is important to let the client know what is the size of the response content. The last request header is followed by two CRLFs; one to indicate the end of the header and another one to indicate the end of the actual headers section. After that, we introduce the response body; a simple hard-coded HTML so that browsers can render a readable “Not found” message to the end users.
Great! Now the main edge cases are handled: when users make any request other than GET they receive a 501, and if they attempt to access an inexistent file they get a 404. Let's test this out with curl:
It's time to compose the response of the happy path, i.e., when the requested file does exist in the system:
Here's a summary of what we've just written:
- First, we read the file info using the
statlibrary. This enables us to figure out the file size and return it in the headers appropriately - Then we compose and send the response headers (with
SOCK_STREAMwe can invokesendmultiple times to return our data while the socket is connected) - After that, we fully read the file and send its content in buffers of 4096 bytes
With this, we finished the implementation of our web server! Below is the final implementation:
To test this out, we can create a simple HTML page in the same directory of the server, and reference some local images and CSS:
When we open the browser and hit localhost:8000/index.html, we should expect to see the HTML page, as well as all the imported assets (i.e. three different files successfully returned by the server) – let's see it in practice:
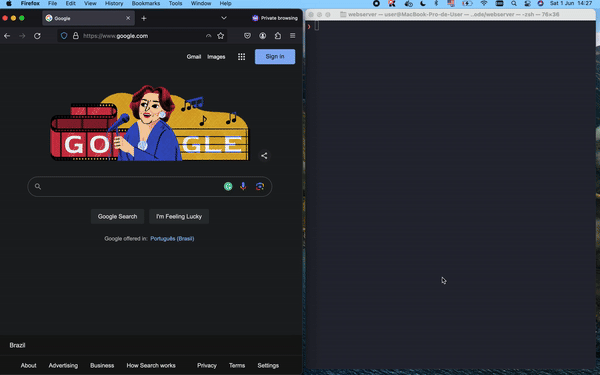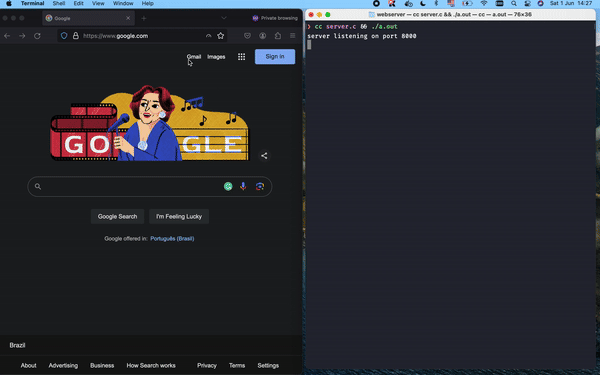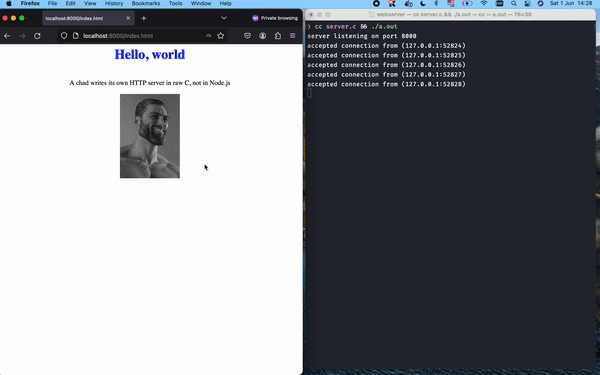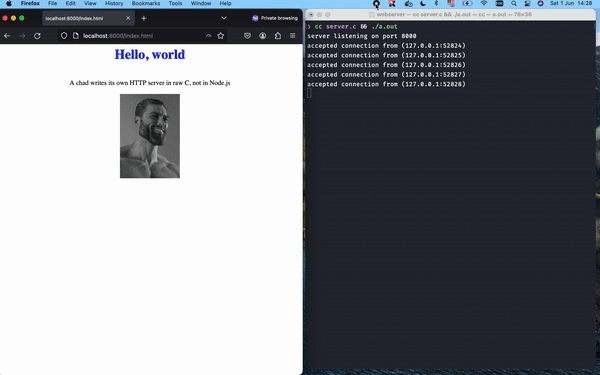
Awesome! We've gone through quite a few interesting topics, from broad things like “What is the web?” and the various layers of OSI and TCP/IP models that compose the Internet, down to actual socket programming in C to consolidate how TCP connections work in practice and how HTTP messages are parsed and composed according to RFC definitions.
The Internet in general is a very complex system and there's a lot more happening under the hood: DNS resolution, Internet Protocol, MAC addresses, and many other physical aspects. However, I hope this post helped other engineers understand more deeply the platform in which they are working every day.
The source code and assets used in the final demo are all available on my GitHub: https://github.com/riltonfranzonee/http-webserver
[1] In fact, people have written whole books covering these layers in great detail. If you want to dive deep into those I recommend “Computer Networking – A Top Down Approach Featuring the Internet” (Kurose and Ross)
[2] In many cases, just 4096 bytes won't be enough to fully read the client's request. As we just need to parse the request URL and method, we simply ignore any additional data.
[3] Image extracted from K&R's book
[4] A full list of HTTP status codes can be found here: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status
[5] Image extracted from K&R's book