Sep 15, 2023
Implementing a Python List in C: an introduction to pointers and dynamic memory management
If your experience in software development is restricted to high-level languages such as JavaScript and Python, you may have gaps in the understanding of some fundamental concepts behind common data structures, like “dictionaries” and “lists”. I’m not saying that abstractions are bad, but it’s essential that you, as an engineer, understand the tools you’re using in your day-to-day work.
Take Python, for example. You can easily set up a list and append all sorts of stuff into it:
When you step down to a lower-level language like C, you realize things aren’t as straightforward as that. You can't just keep piling items into arrays indefinitely, and you certainly can't mix different data types together. Arrays in these languages have fixed sizes and can only hold elements of the same data type or size.
In this post, we'll dive into why arrays, by definition, must have fixed sizes and uniform data types. Then we will implement a basic version of a Python list in C [1], shedding light on the fundamental concepts used by modern high-level languages to implement dynamic and multi-typed arrays.
Why must arrays be homogeneous?
One of the main advantages of arrays is the access time. It doesn't matter whether you try to access an item at index 8000 or index 1, both lookups are bounded above by a constant time, regardless of the element's position or how big is the array.
The key to achieving O(1) access lies in our ability to determine the address of any element at any index without the need to traverse the entire list. But how’s that possible?
Consider this array of integers in C:
On a 64-bit machine, the array would be arranged in memory like this:
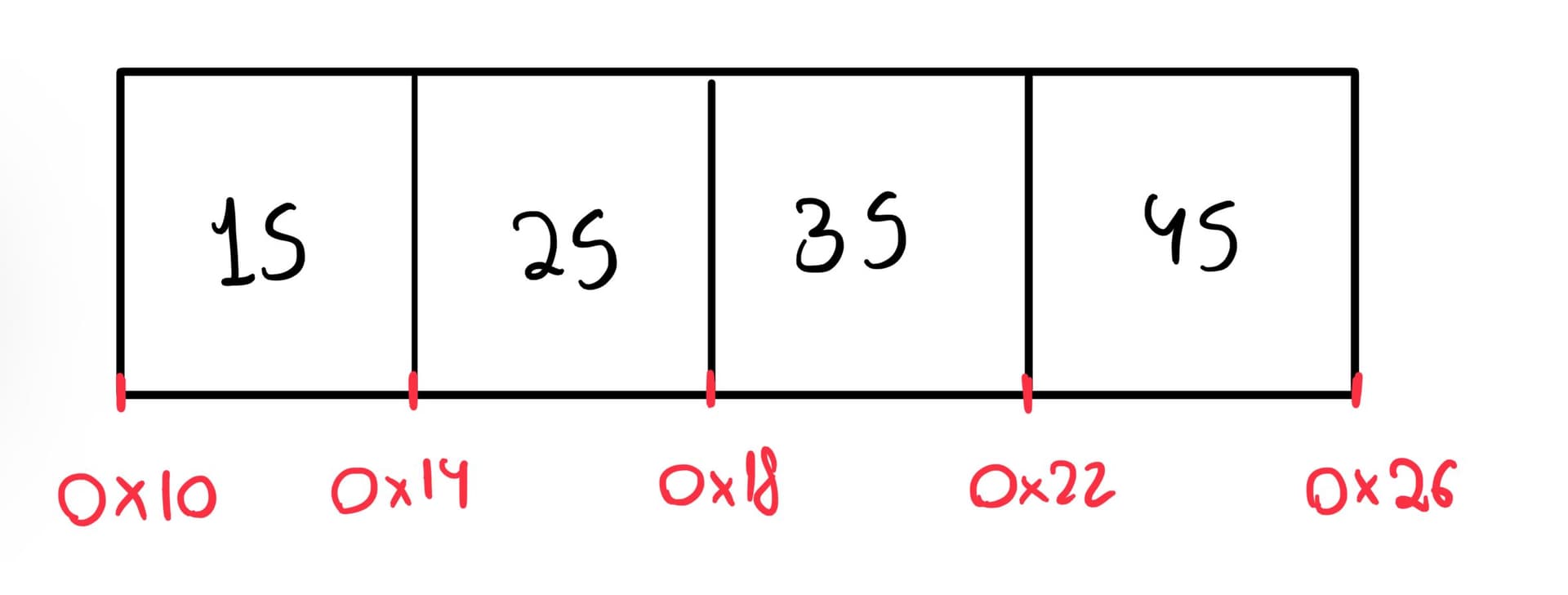
We can see 4 consecutive “slots” allocated in memory, each taking up 4 bytes (i.e., the size of an integer). Knowing the starting address of the array and the size of each “slot”, we can calculate the exact address of any element given its index.
Imagine you’d like to access an element at index 3, for instance. Instead of having to pass through every element in the list up to the desired index, the address could be computed beforehand as:
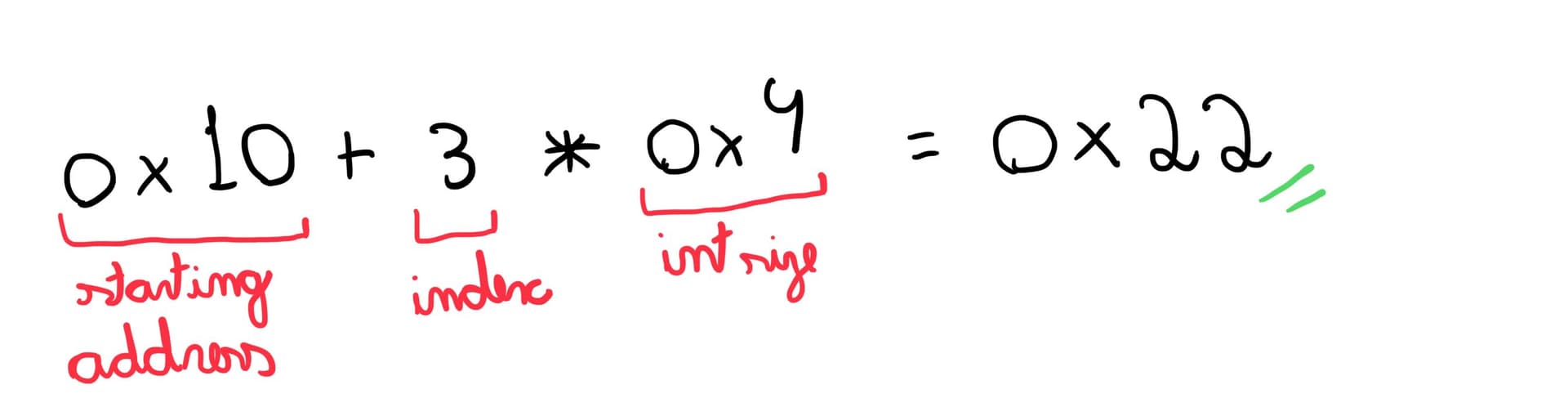
The ability to calculate addresses depends on the fact that all elements in the array are stored contiguously in memory and maintain a consistent size. Otherwise, it would be impossible to predict the location of elements accurately, resulting in a loss of fundamental properties like the O(1) access time that arrays are prized for.
Why must arrays have a fixed size?
Besides maintaining uniform data types, we’ve seen that another fundamental aspect of arrays is that their elements must stored contiguously (i.e., sequentially, side-by-side) in a block of memory.
It doesn’t hurt to remind you, but computer memory is finite. The block of memory used by an array cannot be undetermined; it must have well-defined bounds so that the operating system can ensure no other program modifies or uses the data of our program, and vice-versa.
To create an array of 4 integers, as in the earlier example, the C compiler would allocate 16 contiguous bytes of memory. An array of 5 double-precision floating-point numbers, on the other hand, would need a fixed block of 40 bytes, and so on [2].
Understanding these limitations inherent to the nature of arrays, we can now start talking about how modern languages implement array-like data structures that are capable of expanding dynamically and maintaining elements of distinct sizes. While their implementations may differ here and there for some optimizations, they generally rely on the same fundamental concepts, and those are the ones we’ll be exploring.
An introduction to pointers (and how they can help us achieve heterogeneity)
In simple terms, a pointer is a variable that holds the memory address of another variable. Even though it might sound trivial, this concept is extremely powerful and it’s exactly what allows us to achieve heterogeneity in arrays.
To explore the idea of a pointer, consider the following code snippet:
In this code, num holds the integer value 100, and numPointer stores the memory address of num. A visual representation in memory would resemble the following:
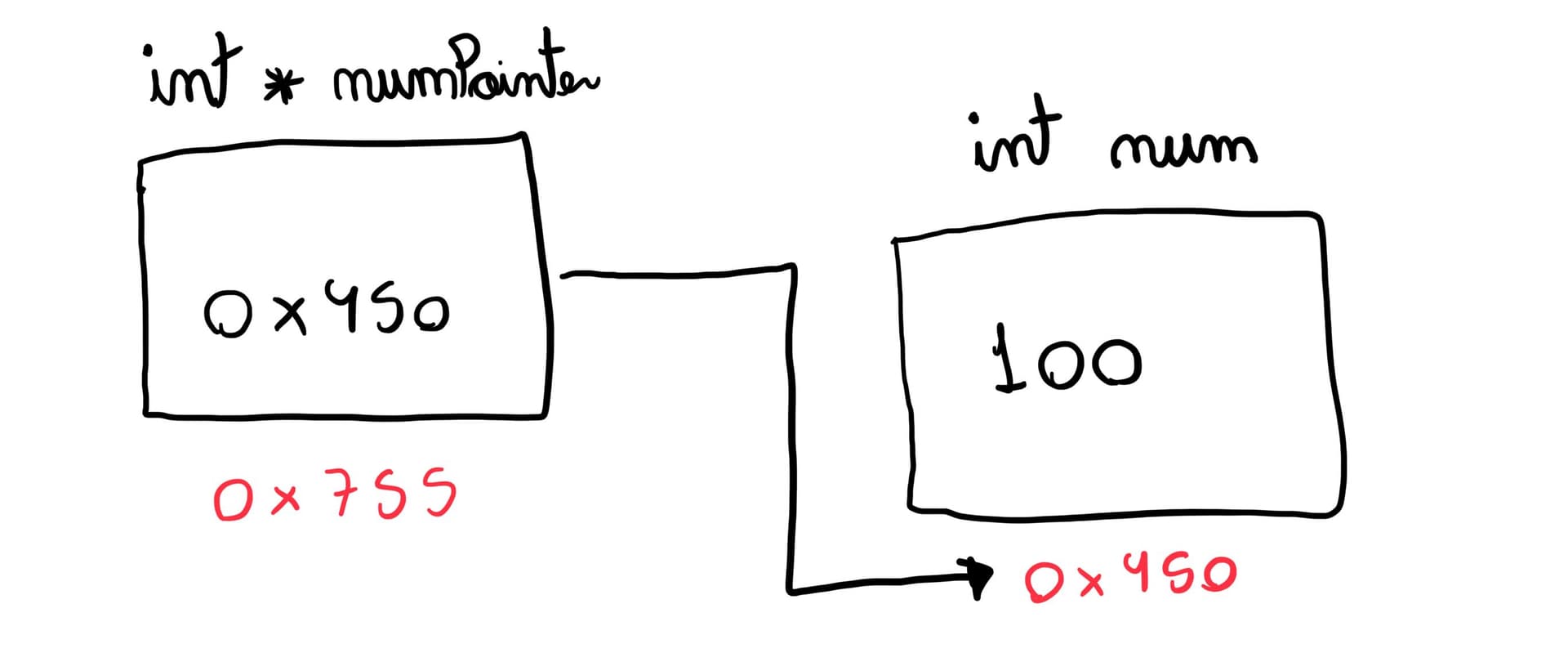
Now, returning to the array problem, where all the items must have the same size, what if instead of storing the actual values in each slot, we store their addresses? Here’s the trick. Ultimately, a “heterogeneous” array is simply a homogeneous array of pointers to other locations in memory, which can then be of different data types and sizes.
Let’s see an example:
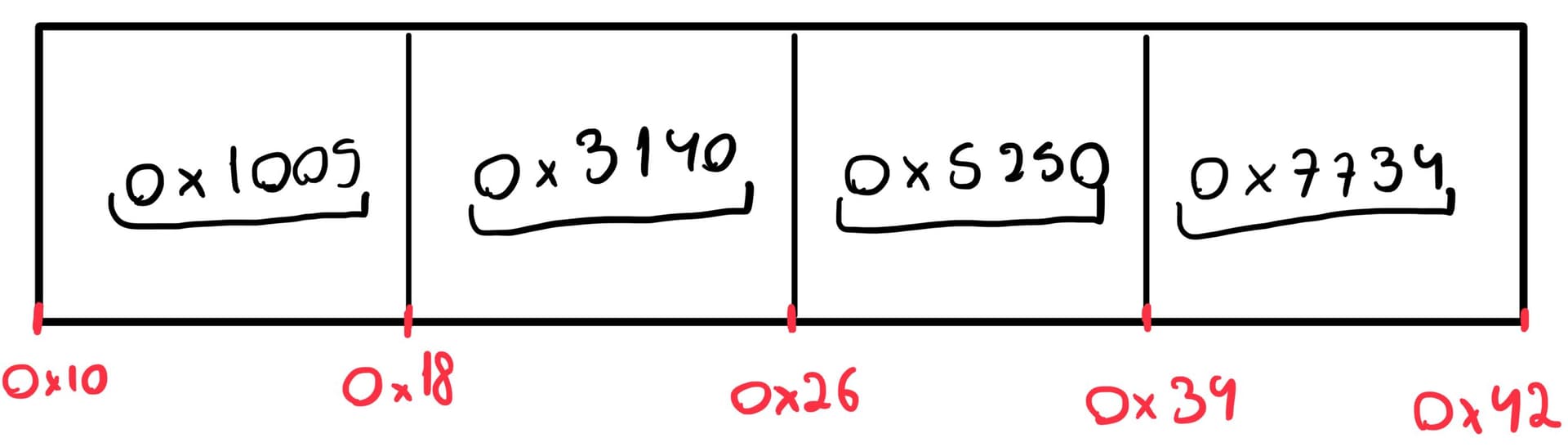
In this representation, 0x1005 could be the location of an integer, 0x3140 could be the address of a float, 0x5250 could be the start of another array, and so forth. However, within the array block itself, all items are simply 8-byte pointers.
This idea lays the groundwork for our list implementation, so let’s get started.
Implementing a Dynamic and Heterogeneous “Array” in C
The first thing we should do is define a struct for our List, including the necessary members to store the array items and handle size changes.
The void** for the “items” member can seem confusing at first look, but let’s break it down.
In the earlier section on pointers, we used an integer pointer as an example (i.e., int*). Now that we’re building a heterogeneous array, we want our elements to be pointers to any data type, not only integers. Therefore we use a generic pointer void*.
The key to understanding the additional * after void* is that, in C, pointers and arrays are strongly related and can often be used interchangeably. When I do void* followed by another *, I’m indicating that “items” is an array of generic pointers.
Additionally, our List struct contains two other members: "capacity" and "length." The "capacity" member represents the maximum number of elements the list can hold, while "length" indicates the current number of elements in the list.
With the struct in place, we’re ready to create a constructor function for the List:
On a normal C array such as int arr[4], the memory is automatically allocated and managed for us on the stack. However, as we want to grow the list dynamically as more items are pushed into it, we need more control over the array and how its memory is managed. To do so, we’ll be using a set of tools from the C standard library that powers up dynamic memory management, starting with malloc.
The default capacity of our list will be 8 elements of void* type. Using the malloc function we can manually allocate the number of bytes needed for it. We’re also using it to allocate the memory for the List struct instance itself.
Great! Moving forward, let's define a basic get function for retrieving elements at a given index:
In this method, I’m using pointer arithmetic to achieve the element at index i. With this syntax, we can think more concretely about pointers: list->items is a pointer to the first element of the array. When I do list->items + i I’m effectively calculating the address of the item at the index i. Then I dereference (i.e., read) the value using the * signal from the address I calculated. This operation is equivalent to something like list->items[i].
It’s also good to ensure we’re not accessing addresses out of bounds, so I added a validation before accessing the element.
The append function is probably the most interesting one. The basic functionality can be written as follows:
As in the get method, I’m also using pointer arithmetic to achieve the element at the index list→length (i.e., the position right after the last item). The main difference here is that now, as the pointer signal is on the left-hand side, I’m writing a value to the end of the current list, rather than just reading it.
This works nicely for the first 8 elements we push, but if we try more than that we will start getting segmentation fault errors, as we haven’t allocated more memory for the “items” array since initialization.
Now realloc comes into play. Similarly to malloc, this function enables us to allocate a number of bytes in memory, but in this case, for an existing block, moving all the elements to another location in compliance with the new number of bytes requested. We can use that to grow the list’s capacity whenever needed:
The idea is that when someone tries to add something to the list and there’s not enough capacity, we double the list's size. While the resizing operation might seem slow (it's O(n)), the append function is actually quite efficient in practice. It doesn’t happen that frequently as the list grows, so when you take a step back and look at it broadly, using amortized analysis, the append function consistently maintains an average time complexity of O(1).
After going through concepts like pointer arithmetic and dynamic memory allocation, the remaining features should be straightforward to implement:
As the name suggests, pop removes the last item from the list and returns it in the response. Note that the location we used to hold the last element does not disappear; instead, we just set it to be a NULL pointer and decrement the length variable. The set function updates the value at the index i with the data received in the arguments.
Last, but not least, we need to write a free function. Remember that we opted for manually allocating and reallocating memory. This is great, but it also comes with a responsibility: we need to manually release the memory we allocated once we’re not using it anymore.
Cool! With this, we’re done with our basic implementation of a dynamic and heterogeneous list in C. Let’s play around and see it working in practice:
This is the output:
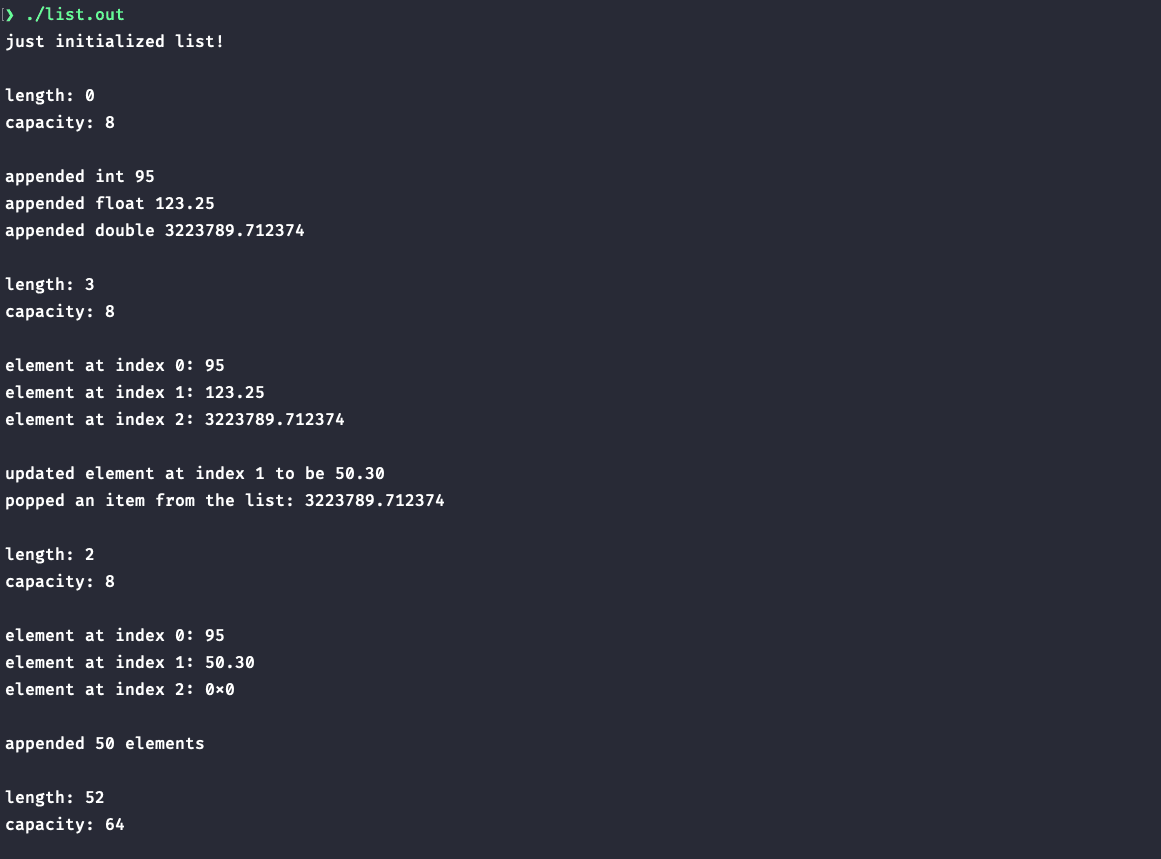
As expected, we were able to push elements of three different types to the list and the capacity automatically expanded as more items were appended.
That’s it for today — thank you for following along! Throughout this post, we explored several interesting concepts and, most importantly, gained a greater understanding of arrays and how they are implemented in modern high-level languages. My plan is to continue writing similar stuff, focused not on framework-specific topics, but on the fundamentals that underpin the technologies we use every day as software engineers.
GitHub repo: https://github.com/riltonfranzonee/list
[1] The first time I implemented this was through an exercise proposed in CS Primer. This is for sure the best resource I found for learning core CS concepts from a practical perspective.
[2] Considering a 64-bit machine, where integers take up 4 bytes, and double-precision floating points are encoded in 8 bytes. By the way, all examples in this post are based on that word size.